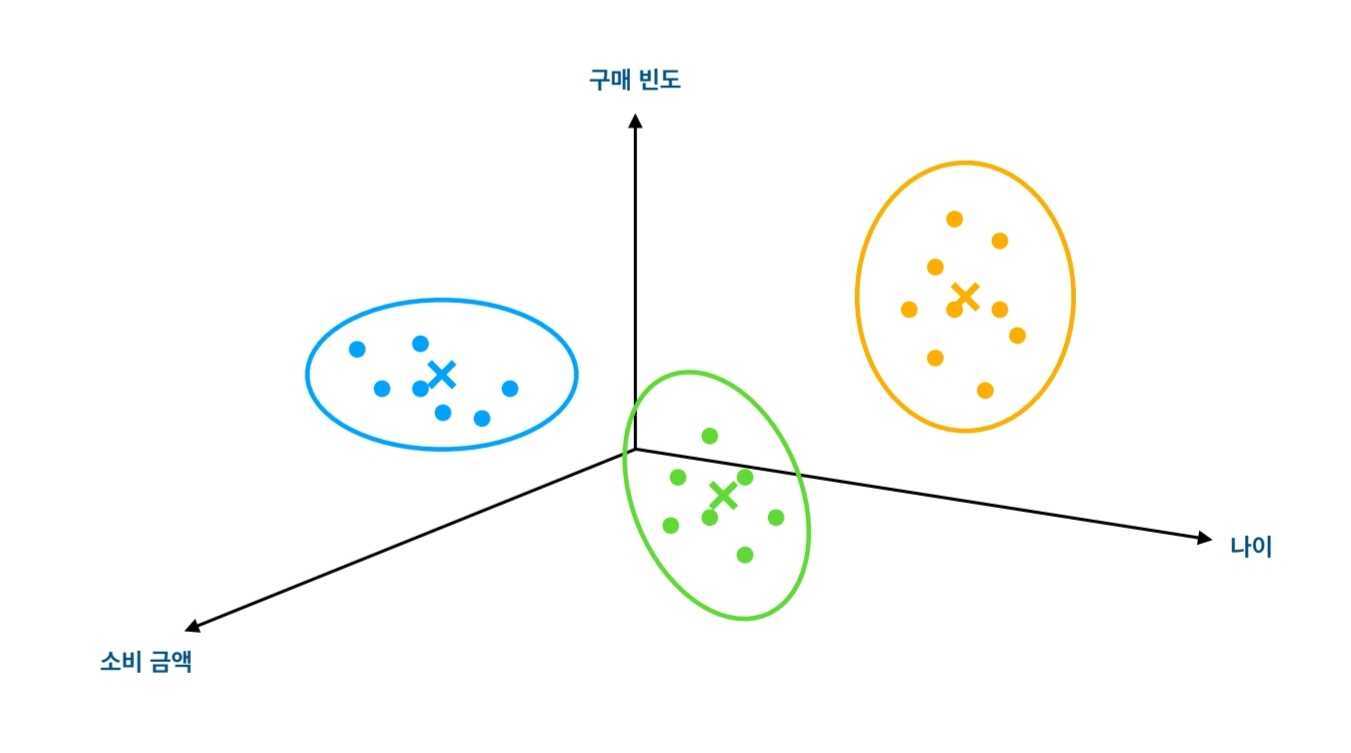
목표 데이터가 없는 비슷한 데이터끼리 묶는 방법
일반적으로 회귀, 분류 문제에서는 추정해야하는 목표 데이터가 라벨링되어있는 데이터를 가지고 모델링을 진행한다. 이를 Supervised Learning이라고 한다.
이에 반해 클러스터링은 명확한 타겟 데이터가 없는 상황에서 비슷한 특징을 가지는 object끼리 구분짓기 위한 모델이다. 지도데이터가 없기 때문에 Unsupervised Learning이라고 부른다.
Clustering Algorithm
그룹을 나누는 기준과 나누는 방법에 따라 여러가지 알고리즘으로 구분되며, 다음과 같은 알고리즘들이 존재한다.
- K-means Clustering
- Hierarchical Agglomerative Clustering
- Mean-Shift Clustering
- EM(Expectation Maximization) Clustering
- DBSCAN
K-means Clustering
이 중 가장 많이 쓰이는 대표적인 클러스터링은 K-means Clustering이다.
이 모델이 가장 먼저 나온 클러스터링 기법임에도 아직까지 많이 쓰이는 이유는
- 빠른 속도 O(n^2)
- 결과가 무조건 나온다는 수렴성(Partition-based hard clustering)
- 간단한 원리에 따른 높은 설명력
이렇게 3가지가 있다.
물론, 그렇다고 단점이 없는 것은 아니다.

- 초기 선택되는 K개의 데이터(initial centroid)에 따라 성능편차가 크다.(2007년 K-means++ 알고리즘으로 이 문제가 어느정도 해결되었다)
- 평균이 의미가 없는 데이터에선 효과가 없다.(K-modes, K-prototype 모델로 해결)
- Outlier에 민감하여 치우친 결과를 내놓을 수 있다.(Outlier 제거 or DBSCAN 모델로 해결)
- 데이터의 분포가 구형이 아니면, 클러스터 생성이 어렵다.
K-means Alogrithm
아무래도 비지도학습의 근본적인 문제인 낮은 설명력의 문제가 가장 적은 모델이기 때문이라고 생각한다.
K-means 알고리즘의 방식은 다음과 같다.
- 랜덤하게 K개의 데이터를 선택하여 기준으로 정한다.
- 선택하지 않은 모든 데이터에 대해서 선택한 K개의 데이터 중 가장 가까운 데이터를 찾는다.
- 가깝다고 정해진 데이터끼리 묶어서 새로운 클러스터를 만든다.
- 새롭게 구성된 클러스터에 속하는 데이터들의 평균을 구한다.
- 새로 계산한 평균을 새로운 K개의 기준으로 정한다.
- 2번 과정부터 다시 반복한다.
- 새롭게 업데이트되는 데이터가 없다면 종료한다.
Objective Function
지도학습에서 Loss function(손실함수)가 있다면, 비지도학습에는 Objective Function(목적함수)가 있다.
K-means Clustering에서는 모든 점과 centroid 사이의 거리의 합이 최소로 하는 것을 '목표'로 하기 때문에 다음과 같은 수식을 통해 목적함수를 설정할 수 있다.
$$ Assume: Z = {z_1, z_2, \cdots , z_K} $$
$$ L(\mathcal{Z},A)=\sum_{i=1}^{N}||x_i-z_{A(x_i)}||^2 $$
따라서, K-means 알고리즘은 목적함수를 최소화하는 방향으로 알고리즘이 진행된다.
'Data Science > Machin Learning' 카테고리의 다른 글
| [ML] Model Evaluation (0) | 2022.11.10 |
|---|---|
| [ML] Feature Engineering (0) | 2022.11.09 |
| [ML] (Classification) Linear Classification (0) | 2022.10.28 |
| AI, 그게 뭔데? (0) | 2022.09.12 |
| Macbook M1 Tensorflow 설치하기(for jupyter notebook) (0) | 2022.09.12 |