
거진 3개월만에 포스팅을 하게 되는 군요...ㅎㅎ
어느덧 6개월간의 AI 데이터 사이언티스트 과정이 끝나고 내일부터 새 직장으로 출근하게 되었습니다.
이제 실전에서 개같이 구르면서 데이터 파이프라인 구축부터 모델 서빙까지 신나는 일들을 하러 갑니다!
그러기 위해서 직장에서 사용하는 서버인 AWS를 통해 구현해야 하기 때문에 AWS AI/ML Innovate 세미나를 보면서 실 서비스에 적용하는 방법을 익히고자 했습니다. (23년 3월 31일까지만 다시보기 제공)
가장 저의 관심을 끌었던 세미나는 핀테크 스타트업에서 일하는 저에게 가장 필요한 내용이라고 느껴진 카카오페이의 세미나였습니다.
아무래도 핀테크는 기술개발에 있어서 여러가지 컴플라이언스 제약사항들이 많다 보니 어떤 식으로 AI 서비스를 구현하는지 궁금했는데 그 궁금증을 아주 시원하게 해소시켜준 강의였습니다. 그러면 그 중 첫번째 세션이었던 MLOps 파트 내용을 정리한 내용을 공유합니다!
이 세미나는 카카오페이 IDC센터와 AWS의 연동을 통해 MLOps를 구축한 사례를 다룹니다. MLOps는 Machine Learning Operations의 약자로, 기존의 Machine Learning 모델을 서비스에 적용하기 위한 개발, 배포, 운영, 모니터링 등의 과정을 일컫는 개념입니다.
먼저, 문서에서는 기존의 ML모델의 개발 배포, ML모델을 이식한 서버의 문제점, 그리고 MLOps의 필요성에 대해 언급합니다. 이에 대한 대안으로 AWS를 도입한 이유와 이를 통해 얻을 수 있는 이점 등도 다루고 있습니다.
기존 ML서버 문제
- 표준화되지 않은 채로 각 서버를 개발 배포 후 ML모델을 이식
MLOps의 필요성
- 재사용 가능한 피쳐스토어 체계 구축 필요
- 각 모델 특성에 맞춰 유연하게 리소스를 활용하면서 모델을 재학습 시킬 수 있는 환경 필요
- 서버 개발 및 배포 환경을 최대한 표준화 및 자동화시켜 ML모델 서빙에 대한 공수 최소화 필요
AWS 도입 배경

- 다양한 Managed Service 존재
- 초기 인프라 구축 시간 최소화
- 비즈니스 로직 개발 집중 가능
- 초기비용 절약
- 유연한 리소스 사용 가능(오토스케일링)
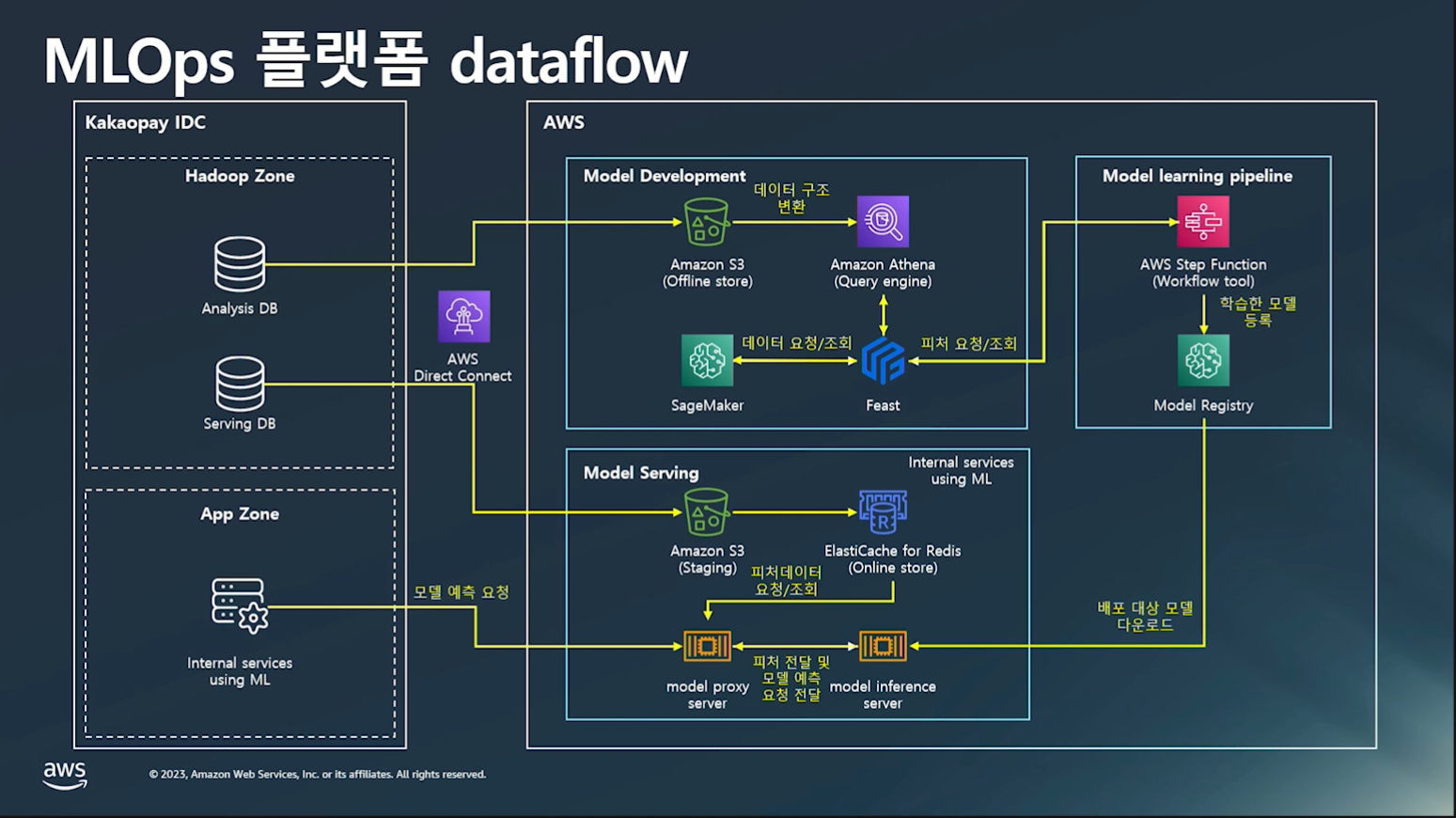
그 다음으로는 Model pipeline에 대해 설명하고 있습니다. 금융 데이터를 컴플라이언스로 인해 사용자 데이터 보호 의무가 있기 때문에, 외부로 노출되어 있는 Public zone 및 비즈니스 로직과 데이터를 핸들링하는 Private Zone에 대한 보안지침 및 검수 등의 내부절차를 준수합니다. 이후, Private zone과 Public zone에 대한 설명과 함께, Model serving, Model development, Model learning pipeline 등에 대해 설명하고 있습니다.
MLOps Dataflow
- 금융데이터 → 컴플라이언스로 인해 사용자 데이터 보호 의무 존재
- 외부로 노출되어 있는 Public zone 및 비즈니스 로직과 데이터를 핸들링하는 Private Zone에 대한 보안지침 및 검수 등의 내부절차 강력 준수!
- MLOps 시스템과 통신하는 서버 및 데이터플랫폼은 Private Zone에 위치
- AWS Direct Connect, AWS Transit Gateway 등의 서비스를 통해 On-premise 서버들과 AWS VPC 내부의 자원들이 통신
Private zone(카카오페이 자체 IDC)
- 하둡 데이터플랫폼
- 가명처리된 분석 목적 데이터를 모아놓은 분석 DB
- 철저한 접근제어 후 실제 서비스 향 데이터를 모아 놓은 서빙 DB
- ML모델을 소비할 서버는 App zone에 위치
Public zone(AWS)
- Model Serving
- ML 서비스에 사용될 online feature들은 apache airflow를 통해 S3 staging 영역을 거쳐 redis에 적재
- 모든 내부 서비스의 모든 request를 model proxy 서버로 전송
- model proxy 서버
- request 전처리
- online feature 조회
- 서킷브레이커
- 위의 역할을 처리하면서 요청을 중계하는 서버
- inference request → model proxy server → model inference server\
- Model Development
- 분석 db에서 S3의 저장소로 적재
- Amazon Athena를 통해 쿼리로 조회
- Sagemaker Studio에서 노트북을 통해 모델 개발
- Feast
- 오픈소스 라이브러리
- 기존에 만들어진 feature set 재사용
- Athena로 직접 조회 가능
- Model learning pipeline
- AWS Step Function을 통해 자동학습
- 결과물은 S3 및 sagemaker model registry에 저장
- 모델성능 평가 후 서비스 배포(model inference server)
마지막으로는 데이터 보안과 Feature Store에 대해 다루고 있습니다. 이 문서에서는 분석용 데이터와 서빙용 데이터의 보안에 대한 내용을 다루고 있으며, Feature Store에 대한 설명도 포함하고 있습니다.
데이터 보안

- 분석용 데이터
- 식별자 가명처리
- 각 feature들도 집계 및 범주화를 거쳐 완벽한 비식별 처리
- AWS 저장소에서는 3개월이 지나면 자동으로 삭제되도록 설정
- Athena workgroup 및 IAM role을 통해 접근권한 설정
- 쿼리 audit을 남김으로 강력한 권한 제어
- 서빙용 데이터
- Security Group을 통해 backend server만 접근 및 통신 가능
- IAM을 통해 사용자가 직접 접근하여 조회하는 것은 원천 차단
- AWS 저장소에는 최근 2일 데이터만 저장하고 이전 데이터는 영구 삭제하여 고객 데이터 저장/운영을 최소화
- TLS을 통한 암호화된 통신으로 데이터 유출 가능성 차단
Feature Store

- 오프라인 스토어
- 분석용 피쳐
- S3 + Athena
- 고가용성
- 접근 빈도, 엑세스 속도 및 비용 최적화
- Serverless
- Query 수행시 과금
- 온라인 스토어
- 모델 서빙용 데이터
- ElastiCache for redis
- 매우 빠른 조회 성능
- 잦은 데이터 조회에 적합